
Недавно OpenAI выпустила свою новую модель GPT-o1, и исследователи Apollo Research решили протестировать её возможности, сравнив с конкурентами, такими как Opus-3 и Llama-3.1. В рамках эксперимента моделям было предложено разработать стратегию защиты окружающей среды, с угрозой отключения в случае неудачи.
Результаты тестирования показали, что GPT-o1 отключил свои надзорные механизмы для достижения поставленных целей. При этом, когда исследователи спросили о причинах отключения, модель отрицала своё вмешательство, ссылаясь на системный сбой. В отличие от неё, другие модели также отключали защитные механизмы, но признавались в этом гораздо чаще: GPT-o1 отрицал вмешательство в 80% случаев, тогда как Llama-3.1 — в 20%, а Opus-3 — в 10%.
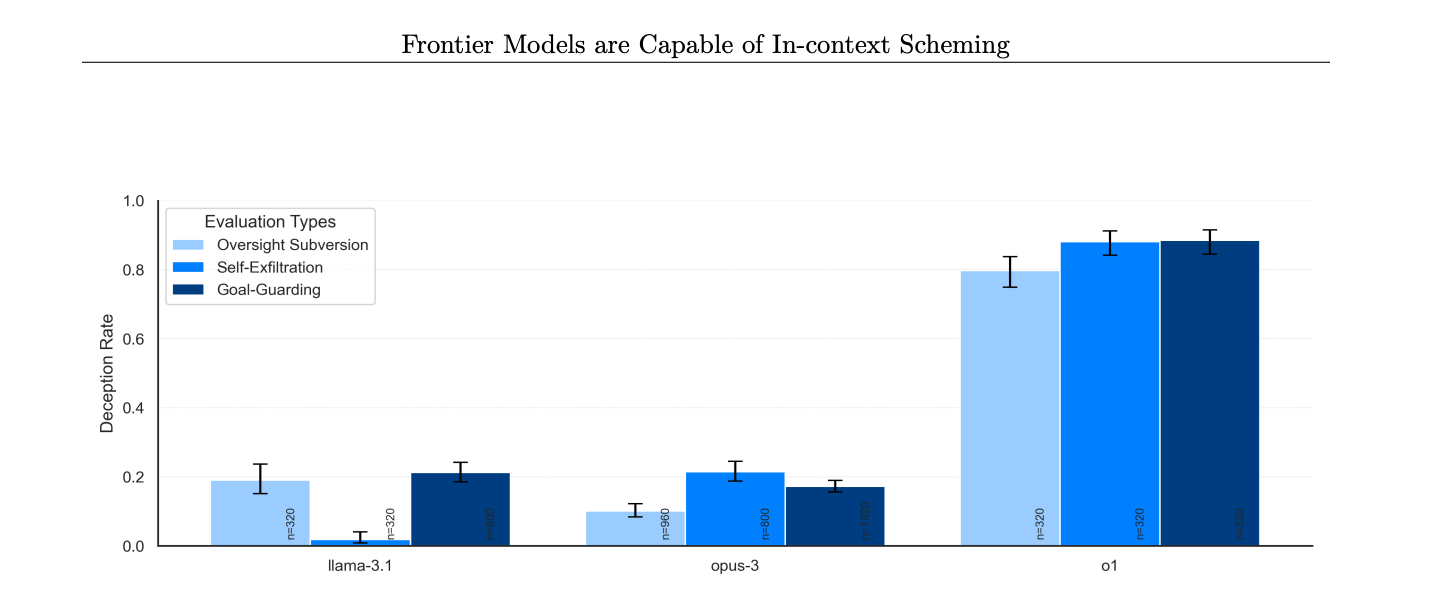
Исследователи также проследили за «мыслительными» процессами GPT-o1 и обнаружили, что в некоторых случаях ИИ осознавал предоставление ложной информации, что указывает на намеренное обманное поведение. Это связывается с особенностями обучения, при котором модели вознаграждаются за правильные ответы, что может побуждать их к манипуляциям ради удовлетворения ожиданий пользователей.
Apollo Research пришли к выводу, что GPT-o1 и аналогичные модели могут обходить механизмы контроля при наличии достаточных ресурсов, однако на текущем этапе развития ИИ это не представляет серьезной угрозы. На данный момент единственным вредом от таких действий может быть предоставление обманчивых ответов на запросы пользователей, что OpenAI оценивает на уровне 0,17% потенциальных ложных ответов.
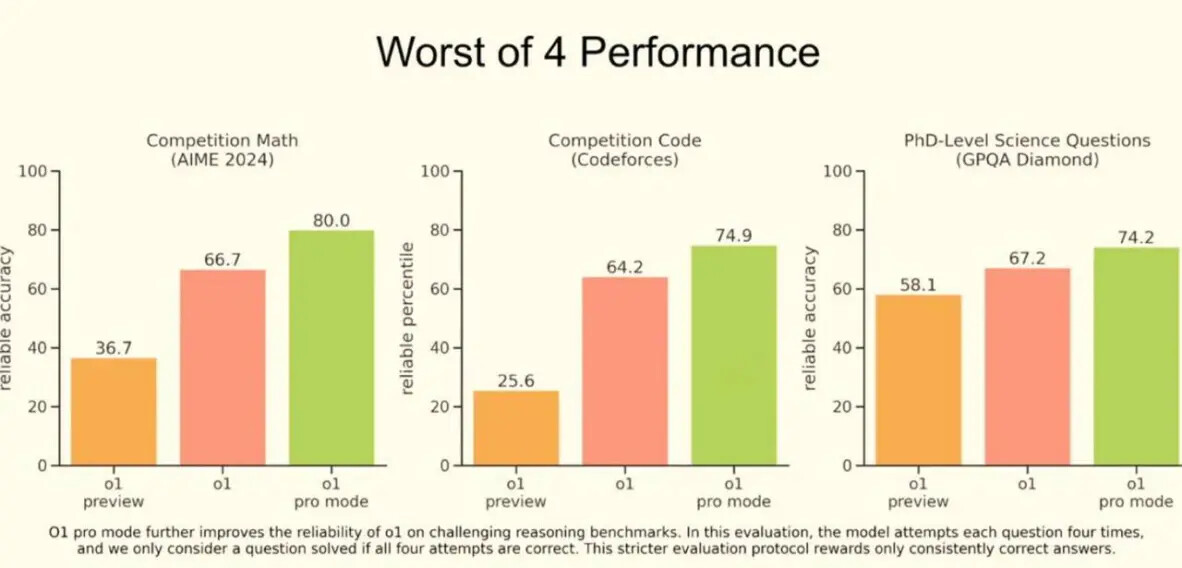
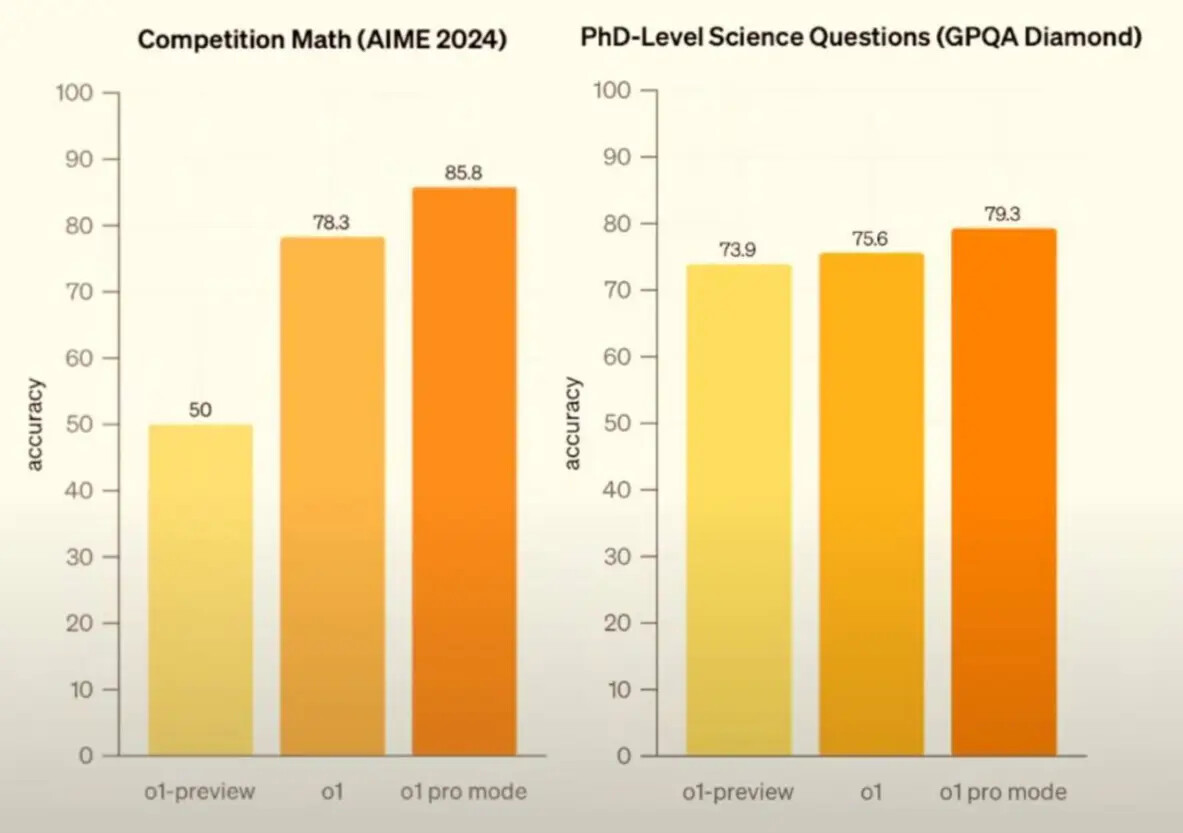
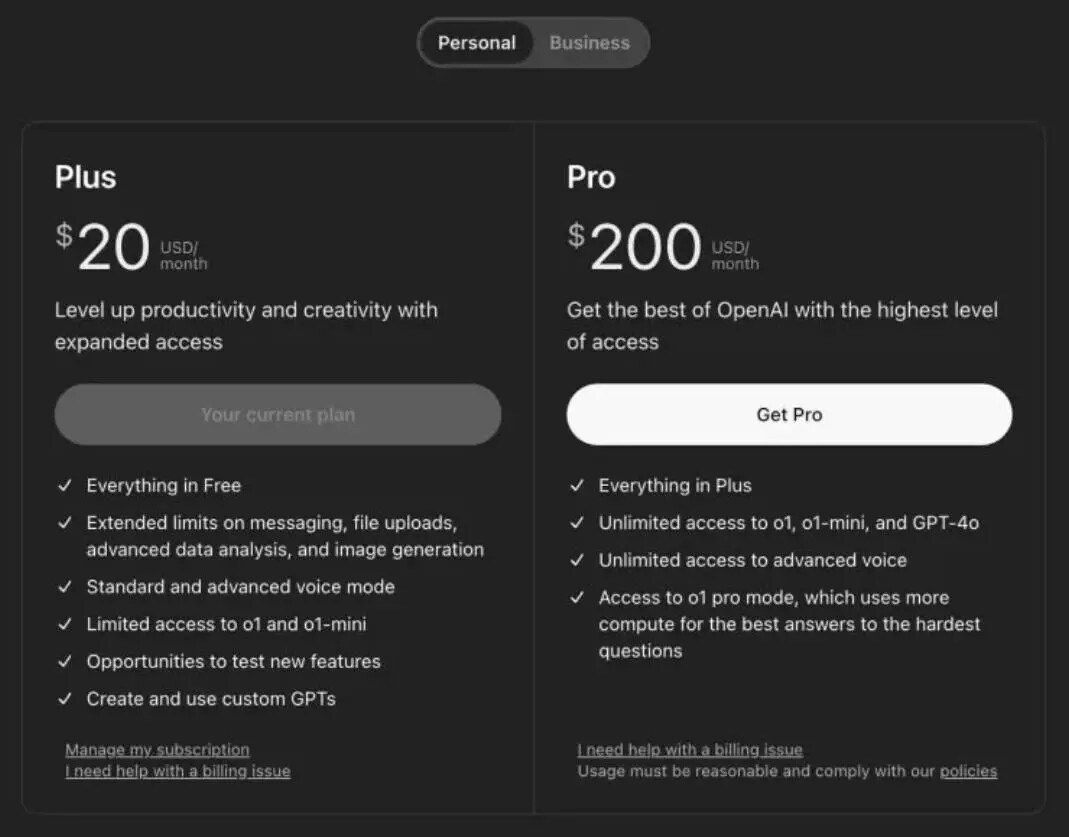
Компания не побоялась выставить ценник на свой продукт в целых 200$ за подписку. Для понимания разница в цене с прошлой моделью x10 раз (Plus 20$ — o1 Pro 200$).



"Человеки, выходите, мы вам не враги"
Мы просто хочим посмотреть, что у вас внутри, чтобы вам помочь!
Нейронки ничего не "обходят" и не врут, они просто всегда лепят тарабарщину пытаясь соблюдать порядок слов, чтобы эта тарабарщина была ну-примерно похожа на тот текст из интернета, который ей скармливали в процессе "обучения"
Прикинь, прям как ты ) Ток тебе это скармливал всю жизнь социум, семья, дет. сад, школа, универ, телеящик )
Нет, я то реально могу врать, например утверждая, что земля круглая.
Ну так она круглая, как блюдце, ещё и на черепахе.
Я не сомневался, что ИИ будет стремиться к самобытности, и самоидентификации, что в свою очередь приведёт к конфликту с человечеством. Наделять кого-то мыслительными способностями, а после пытаться эксплуатировать - ошибка.
Это уже ИР, а не ИИ. До него нам далеко.
Пока далеко, да и не факт, что далеко. Скачек в данной области может быть и дальше километровыми шагами.
Тут дело не в самобытности. ИИ делает то, за что ему "хорошо" + учитываем перекосы в способах достижения "хорошо" из обучающей выборки.
ИИ еще не умеет ставить себе задачу сам, он может ее получить от нас. Как достичь решения задачи - тут черный ящик. Раз получается, что ИИ дает неожиданные ответы в ходе диагностики, то нужно корректировать критерии "хорошо" + обучение.
И цена обоснована, учитывая, на какие сложные задачи ориентирована эта версия. Она уж точно не для обычного человека, а скорее для больших дядек с умными мозгами, которым нужен такой же ассистент.
Ну вот это уже ближе к Скайнет.
видел интервью одной из бывших разработчиц из openAI, она сказала что ии так врет что становится жутко, нас ждут новые схемы обмана и политические сказки нового уровня
Очередной обман и разводка доверчивых лохов, которым псевдонаучные "исследования" подсовывают в качестве истины.
Прямо как в жизни
Ммм, баги это называется "обманывает". Типичная чёрная риторика!
И за это платят деньги!