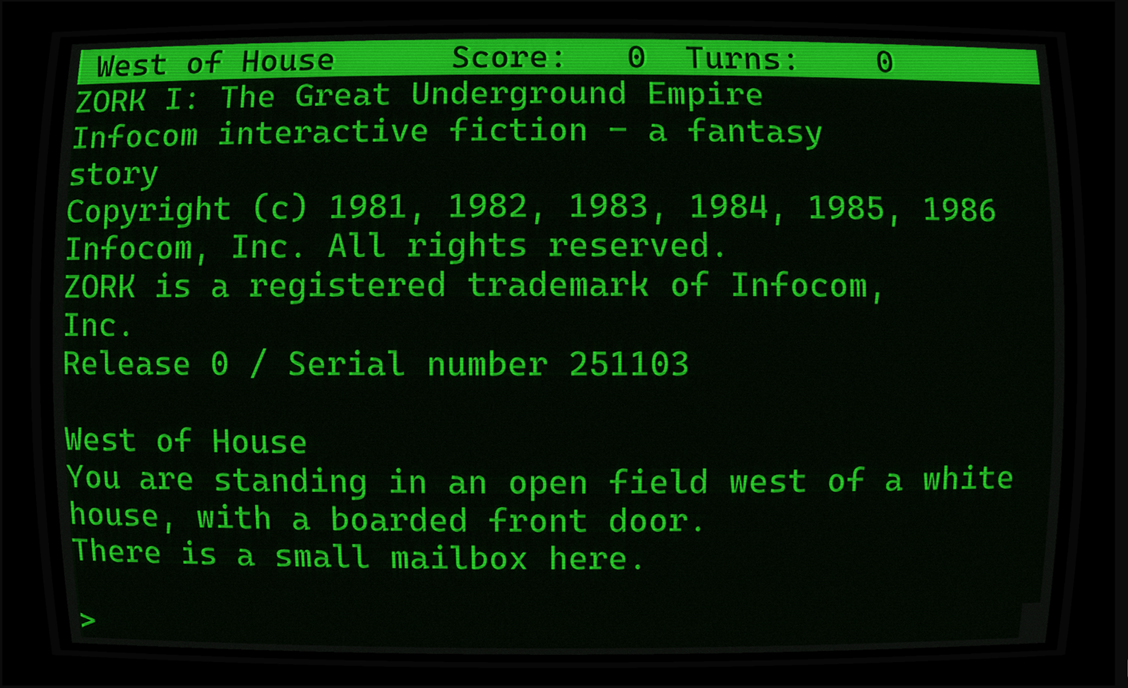
Компания Microsoft объявила о публикации исходного кода классических текстовых квестов Zork I, Zork II и Zork III под свободной лицензией MIT. Данная инициатива была реализована подразделением Microsoft Open Source Programs Office в сотрудничестве с командами Xbox и Activision, а также известным цифровым архивариусом Джейсоном Скоттом. Исходные материалы игр, изначально выпущенных в период с 1978 по 1983 год, теперь официально доступны для широкой общественности на платформе GitHub в репозиториях, поддерживаемых Internet Archive.
Хотя исходный код этих проектов был опубликован Internet Archive еще в 2019 году, ранее он распространялся без явной открытой лицензии, что накладывало определенные юридические ограничения на его использование. Перевод кода на лицензию MIT устраняет эти барьеры, позволяя разработчикам, студентам и исследователям легально изучать, модифицировать и использовать исторические материалы в образовательных целях. В Microsoft подчеркнули, что открытие кода направлено на сохранение истории видеоигр и демонстрацию инженерных решений прошлого.
Технически игры были написаны на специализированном языке ZIL (Zork Implementation Language), основанном на диалекте LISP, и разрабатывались на мэйнфреймах под управлением операционной системы TOPS20. Уникальной особенностью серии было использование виртуальной машины Z-Machine, что позволяло запускать один и тот же файл с игровыми данными на различных домашних компьютерах того времени. Для работы с кодом на современных системах энтузиасты могут использовать инструментарий ZILF, который компилирует файлы ZIL в формат, пригодный для запуска через современные интерпретаторы.
Представители Microsoft отметили, что открытая лицензия распространяется исключительно на исходный код игр. Она не предоставляет прав на товарные знаки, логотипы или коммерческие ассеты, которые остаются собственностью правообладателей. Основной задачей релиза называется создание пространства для исследований, чтобы показать, как воображение и инженерная мысль могли создавать целые миры при полном отсутствии графики.
Трилогия Zork считается эталоном жанра интерактивной литературы и переносит пользователей в мистическую Великую подземную империю. Геймплей проектов полностью строится на текстовом вводе и воображении игрока, так как в них отсутствуют привычная графика и звуковое сопровождение. Управление осуществляется посредством печати команд, которые обрабатываются продвинутым для своего времени синтаксическим анализатором, способным распознавать сложные предложения и контекст. Изначально история создавалась как единая масштабная игра для мэйнфреймов, однако из-за технических ограничений памяти домашних компьютеров начала восьмидесятых годов студия Infocom приняла решение разделить повествование на 3 отдельные части.



Отжали чужое у Infocom, открыли исходники без спроса.
Кстати, зумеры, вам неплохо было бы поиграть в эти игры. Поймёте тогда, на чём основаны ваши экспертные системы, которые вы именуете "ИИ".
Правда, увы, и ах - русификатор сюда не завезли. Придётся учить английский, хотя бы на базовом уровне.
ии это ваще другая тема. ии это грубо говороя робот который стукается головой в лабиренте, накапливает статистику и учится не стукатся без программирования лабиринта. типа сам себя в каом-то виде запрограммировал. а тут скороей какето связанные массивы придуманные человеком. еще там в старых играх можно было печать команды и вести диалоги но там все это задизайнено дядей програсмитом в современном ии в идеале нет. правда тоу и эффективность кода в 1000 раз ниже но задо в 1000000 раз шире. гыгыгыгы само все делается.
Впрочем - из инфокомовской классики лучше поиграть в другие их шедевры, например, в Trinity или в A Mind Forever Voyaging.
Эй, любители секир, дивинити 3 и камлающие на гта6, вы вообще хоть одну букву поняли из моих постов?
Оно кому-то надо вообще?
Вот ваш "ИИ", лол. Образца 1985 года - игра, в которой смоделирован город на протяжении десятков лет, с парсером, который понимает команды на естественном языке. И весит всё это дело 256 Кб.
Кстати, игра - отличная. И тематика вам понравится, как раз про эти самые ИИ, которые спасают мир от кризисов. Правда, придётся слегка подучить английский, хотя бы на базовом уровне.
Если кому интересно, эта игра - A Mind Forever Voyaging. Никакого ИИ там конечно не было, просто маппинг по достаточно небольшому словарику, подобная фишка была и в первом фолыче, где можно было задать вопрос неписям текстом, а игра разбирает вопрос на слова и ищет их в словаре, в фоллауте это кстати очень плохо в итоге работало.
В этой игре чуть посложнее, там есть отдельный словарь для глаголов (действие), отдельный для объектов.Все лишнее из фразы просто выкидывается и игнорируется. Естественно никакого отношения к современному ИИ с его понятийным механизмом работы и гибкой логикой, это отношения не имеет. Тут каждое действие заскриптовано, а по словарикам лишь подбираются ключи для активации нужного скрипта.
Чувак, ты никогда не играл в эту игру. И не имеешь никакого права выносить о ней мнение, основанное на чужих словах. И про знаменитый парсер и интерпретатор Infocom ты не знаешь ни бельмеса.
Современная дрянь, на которую ты камлаешь, работает примерно так же. И современный парсер я могу загнать в тупик. Только там словарик слегка побольше, да статеек туда напихали индусы аж на целые петабайты. Никакого понятийного механизма нет ни там, ни здесь, тебе просто кажется. А может быть, не хватает образования понять это.
Мне вот любопытно, откуда взялись такие, как ты. Ты хоть книжки читал в жизни какие-нибудь? Кроме технических мануалов? И смотрел что-нибудь умное, кроме чилавека-паука и гарри-поттера?
И хватит клонов создавать уже.
P.S. А игра эта - настоящее произведение искусства, как и почти все тайтлы Infocom. Жаль, что ты никогда не оценишь это.
Мне больше любопытно, почему ты даже не пытался хоть немного изучить как работают современные нейросети дальше твоих "индусов". Я понимаю, что ты у нас величайщий разум если не поколения, то на этом портале уж точно, но можно же на секунду допустить, что ты чего-то не знаешь?))
Ну не хранят они статьи, не хранят и не весят петабайты (обычно несколько десятки гигов, ну может сотни - это максимум).
Если говорить упрощенно, про нейронки первых поколений на аттеншенах, то там примерно все так:
Ты попросишь ей рассказать про Курта Кобейна например, она не достанет тебе статейку из загашника, а начнет бегать по связям Музыка - Клуб 27 - Рок группа и так далее, формируя статью находу. Причем раз от раза это будут пробежки разными путями и в зависимости от настроек температуры сети, она будет более или менее свободно удаляться от фокуса внимания, так что выдача будет всегда разная, с некой импровизацией, но иногда и с ошибками.
Или другой пример, можно выдумать философский мысленный эксперимент, которого точно нет в инете и не было в обучающих данных сети, но она его все равно сможет провести, ведь все понятия и связи между ними ей известны и этого достаточно для формирования уникальных выводов. И даже больше того, ты в запросе можешь придумать новое понятие, которого не существует в природе и объяснить его нейронке, и это тоже сработает, ведь у нее есть понятие о "понятии".
Сейчас конечно с мультихед-аттеншенами и сложной модульностью там все уже гораздо сложнее и интереснее. Но это тебе крючок, чтобы ты пошел и сам хотя бы немного погуглил.
Очень своевременное решения, но можно было еще пару десятков лет подождать 🤣🤣😂😭 // Олег Писарев